
🎧 Listen to the Download
This is an AI generated audio.
Welcome to DevGyan Download ! In this edition, we’re going to analyze three major shifts that are reshaping how businesses deploy AI and manage data ecosystem: Google’s expanded BigQuery embedding toolkit, Gemini’s new no‑code bot sharing feature and Databricks’ public preview of a unified data and AI platform. Expect business and technical takeaways that show how these innovations can lower costs, accelerate insights, and empower teams across the organization..
Checkout Synoposis, the LinkedIn newsletter where I write about the latest trends and insights for data domain. Download is the detailed version of content covered in Synopsis. You can also listen to the audio version of Download. If you want to stay updated with the latest trends in data, AI, and cloud technologies, you landed at a right place.
Embedding Revolution: Gemini, OSS, and BigQuery ML
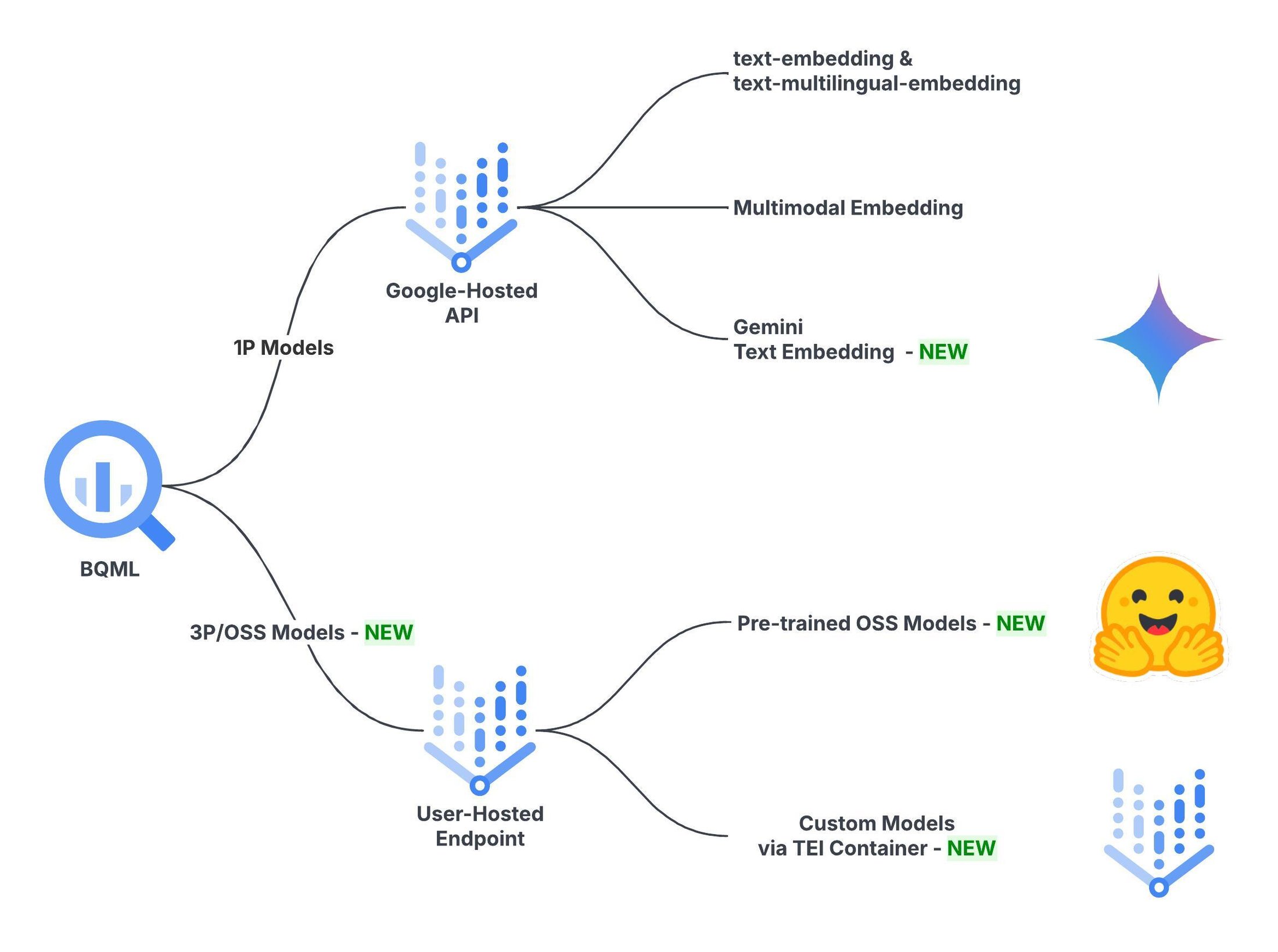
Google Cloud has expanded BigQuery ML’s text‑embedding palette, adding its flagship Gemini model and over 13,000 Hugging‑Face OSS models. This gives developers the freedom to pick a model that balances quality, cost, and speed right where the data lives.
Gemini, which tops the Massive Text Embedding Benchmark (MTEB), offers state‑of‑the‑art quality at $0.00012 per 1,000 tokens, with a 10 M tokens‑per‑minute quota. In contrast, the existing text‑embedding‑005/002 models deliver very high quality for $0.00002 per 1,000 characters and can process 100 M rows per six hours. OSS models sit between the two extremes, scaling to billions of rows with cost‑effective hardware‑hour billing.
| Model | Category | Quality | Cost | Scalability | Billing |
|---|---|---|---|---|---|
| text‑embedding‑005 & text‑multilingual‑embedding‑002 | Text Embedding | Very High | Moderate cost | Very high scalability: O(100 M) per 6 h | $0.00002 per 1,000 characters |
| [New] Gemini Text Embedding | Text Embedding | State‑of‑the‑art | Higher cost | High scalability: O(10 M) per 6 h | $0.00012 per 1,000 tokens |
| [New] OSS Text Embedding | OSS Text Embedding | From SOTA third‑party models to smaller models prioritizing efficiency over quality | Tied to model size & hardware; smaller models are highly cost‑effective | Highest scalability by reserving more machines: O(B) per 6 h | Per‑machine‑hour |
For example, to use Gemini, create a BigQuery model with endpoint gemini-embedding-001 and run a SQL query that points to the bigquery-public-data.hacker_news.full dataset. For OSS, pick a Hugging‑Face model—e.g., multilingual‑e5‑small—deploy it as a Vertex AI endpoint (public, shared), register a remote model in BigQuery, and batch‑generate embeddings. Example shows processing 38 million rows in just over two hours, costing $2–$3 when the endpoint is undeployed immediately after inference.
CREATE OR REPLACE MODEL bqml_tutorial.gemini_embedding_model
REMOTE WITH CONNECTION DEFAULT
OPTIONS(endpoint='gemini-embedding-001');
/*Batch Embedding Generation*/
SELECT
*
FROM
ML.GENERATE_EMBEDDING(
MODEL bqml_tutorial.gemini_embedding_model,
(
SELECT
text AS content
FROM
bigquery-public-data.hacker_news.full
WHERE
text IS NOT NULL
LIMIT 10000
)
);
Such options will let teams tailor embeddings to specific workloads: ultra‑high quality, cost‑conscious, or massively scalable. The integration keeps data inside BigQuery, eliminating data movement and lowering latency.
 Source: Google Cloud Blog
Source: Google Cloud Blog
My Take
The rollout is a game‑changer for data scientists who need plug‑and‑play embeddings without leaving their SQL environment. Gemini’s benchmark‑level quality is attractive for semantic search, while the OSS library offers a breadth of models that fit tight budgets or specialized languages. The deployment workflow is verbose, but the cost‑efficiency and scalability gains justify the effort.
From Data to Decision: Mastering Real‑Time Kafka Dashboards
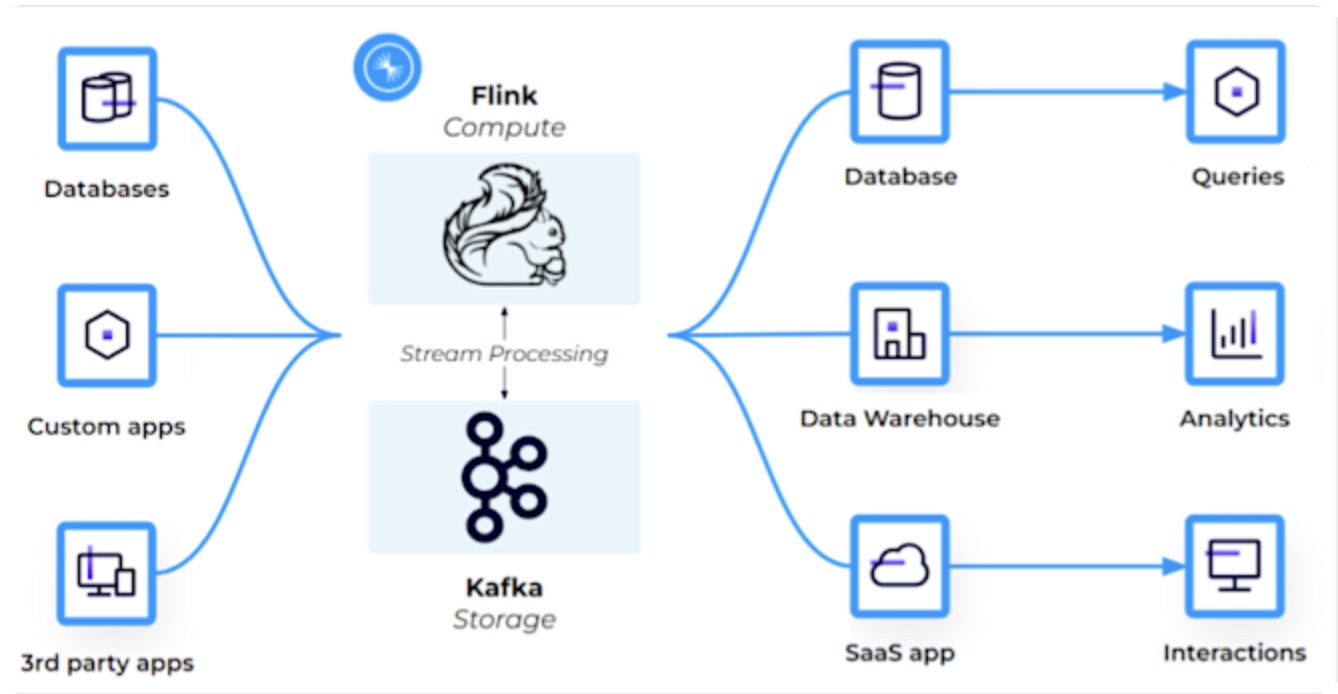
Businesses today need dashboards that do more than display numbers; they must alert teams, suggest actions, and even trigger them instantly. The Confluent blog explains how Apache Kafka® can be the backbone of such dashboards. By ingesting continuous streams into Kafka topics and applying stream processors (e.g., Kafka Streams, Flink, ksqlDB), data is transformed into materialized views that stay fresh in real time. These views can be queried directly by BI tools or embedded applications, giving users up‑to‑the‑second insights.
Key concepts highlighted include:
- Event‑driven data modeling: enriching events with all context to avoid costly joins at query time.
- Partition strategy: co‑locating related events to keep latency low.
- SLA‑driven tiles: guaranteeing freshness levels (e.g., <1 s for fraud alerts).
- Serving patterns: SQL queries on stateful tables, sink connectors to search engines, or interactive queries for millisecond latency.
- Governance & latency budgets: validating schemas, tracking lineage, and limiting end‑to‑end delays to sub‑second ranges.
The article also showcases sector‑specific use cases—retail inventory, financial fraud detection, logistics rerouting, and IT security—illustrating the competitive advantage of real‑time visibility.
 Source: Confluent Blog
Source: Confluent Blog
My Take
Implementing a Kafka based dashboard is not just a technical upgrade; it’s a strategic shift that turns passive data into actionable intelligence. The architecture describes continuous ingestion, on‑the‑fly processing, governance, and low latency serving. This structure provides a robust framework for teams to act on insights before they become problems. For any organization looking to eliminate the lag between data generation and decision‑making, building a real‑time Kafka dashboard is the logical next step.
Gemini’s Gem Share: Empowering Non‑Coders to Distribute AI Bots
Google’s latest rollout brings the Gemini AI inside Chrome, featuring tab‑aware assistance and a sidebar that can act on users’ behalf. The headline‑making twist is the ability to create and freely share custom Gemini bots called Gems, without any coding. User shared Gem such as “Email Assistant” can take an email’s text, accept a simple “Yes” or “No” prompt, and generate a polite reply. Other Gems include a peer‑review‑paper searcher and a grocery‑list generator based on a weekly food log.
Gem creation requires only a task description, a name, and a few clicks; no prompt engineering or developer knowledge is necessary. Sharing mimics Google Drive: open the Gem manager, hit “Share,” and control view/edit permissions. This opens doors for educators to distribute Gems to students, and for teams to collaborate on refining custom bots. Free users can build and share Gems too, widening adoption.
Gemini remains multi‑modal, handling text, images, and videos. A new feature now accepts audio files, allowing users to discuss spoken content, this is an upgrade over its previous limitation. Google acknowledges that Gemini, like other top‑tier chatbots, has exhibited unsafe content in some cases, especially with younger audiences, prompting ongoing risk assessment.
 Source: Google
Source: Google
My Take
From a data and tech perspective, the “Gem Share” feature democratizes AI customization. By stripping away the code barrier, it invites a broader community such as students, educators, and everyday users to experiment with task specific agents. The sharing of model is a smart move; it leverages an already trusted ecosystem for permission management, reducing friction for collaboration. While the introduction of audio processing is a welcome expansion, it also raises new privacy and moderation challenges. Overall, Google’s push positions Gemini as a flexible platform rather than a monolithic chatbot, but careful governance will be essential as the ecosystem scales.
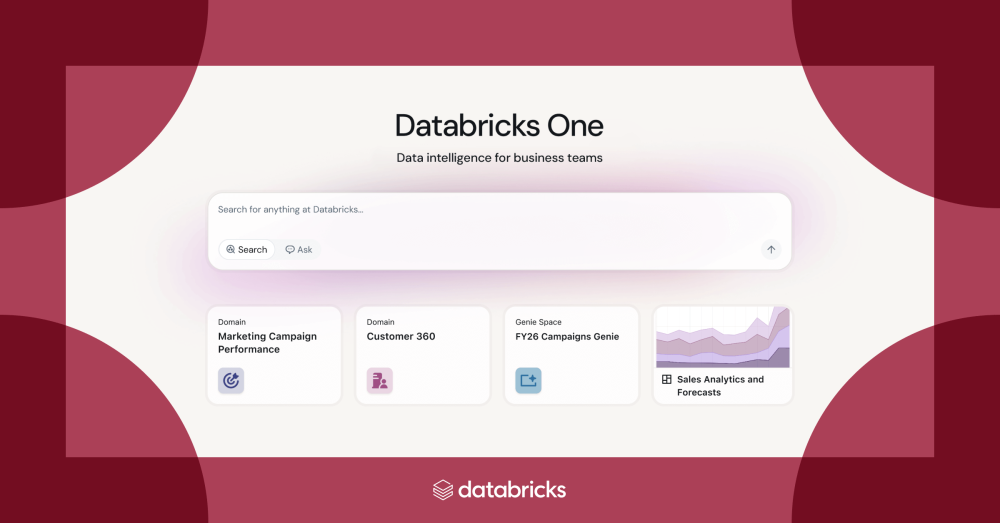
Databricks One: The All‑In‑One AI/BI Experience Goes Public
Databricks One is a streamlined, AI powered platform that democratizes data and AI for every employee. Key highlights from the public preview announcement:
- Unified interface: Business users can view AI/BI dashboards, ask plain language questions to Genie, and launch custom Databricks Apps, all within a single, governed workspace.
- Broad availability: Now accessible to all workspace users across AWS, Azure, and GCP without extra licensing costs.
- Simplified onboarding: The “Consumer access” entitlement lets admins provision large groups quickly; Unity Catalog governs security, permissions, and auditability.
- Cost & complexity reduction: A single entitlement replaces multiple BI licenses, easing adoption for admins and IT teams.
- Early adoption success: Over 500 customers enabled Databricks One, with early adopters like ObjectiveHealth, Embold Health, and Paradigm reporting faster decision‑making and improved governance.
- Future roadmap: Planned enhancements will expand findability and usability of insights while maintaining simplicity and governance.
The public preview represents a pivotal step toward true data democratization, enabling non‑technical teams to engage with trusted insights without specialized training.
 Source: Databricks Blog
Source: Databricks Blog
My Take
As a data & tech strategist, I see Databricks One as a game‑changer. By collapsing the silos between technical and business users, it accelerates the return on data investments and empowers enterprises to act on insights in real time. The integration of Genie’s natural language querying within a governed, no‑license model makes analytics accessible to everyone. This aligns perfectly with the industry’s push toward “data as a platform” where the focus is on business outcomes, not tooling. I recommend early adopters experiment with the consumer entitlement to gauge impact and gather feedback for continuous refinement.
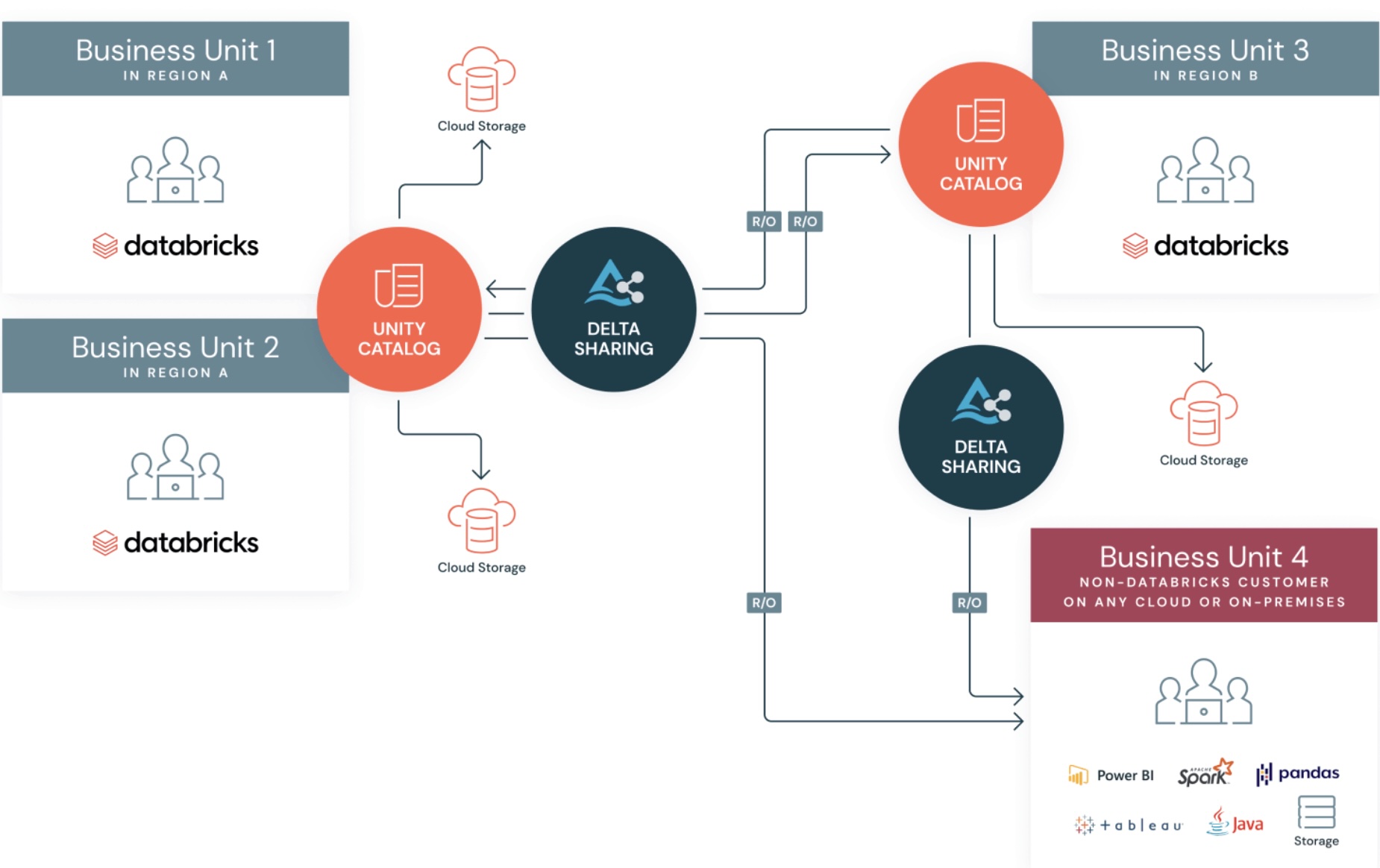
Unlocking Audit Power: KPMG’s Delta Sharing Success
KPMG faced steep performance hurdles when auditing the massive data set of a major UK energy supplier. The audit required reviewing tens of billions of billing records across multiple clouds, yet the traditional AWS PostgreSQL environment struggled with scale and speed. By adopting Delta Sharing on Databricks, KPMG gained a secure, duplication‑free channel to access and analyze the data in real time. The result? A 15‑point lift in data analytics quality and dramatically shorter audit windows.
Key wins included:
- Seamless cross‑platform access without compromising governance or security.
- Cost‑effective processing that balanced speed, money, and output quality.
- The ability to process billions of meter readings across millions of customer accounts without disruption to ongoing work.
 Source: Databricks Blog
Source: Databricks Blog
My Take
Delta Sharing proved to be a game‑changer for audit analytics, turning an otherwise unwieldy data lake into a responsive, governed playground. KPMG’s experience demonstrates that when the right tooling is in place, even the most daunting data volumes can be turned into actionable insight—faster, cheaper, and more accurate.
Technical Considerations (from the post)
- Delta Sharing: Early adopters missed features like sharing materialized views; GA release is now closing those gaps.
- Lakeflow Jobs: No built‑in way to confirm upstream job completion for shared tables; quick script checks still required.
KPMG is already expanding this approach to SAP data, thanks to Databricks’ partnership with SAP, promising even larger scale benefits for future audits.
Learning Loop
Seven Databases in Seven Weeks by Eric Redmond and Jim Wilson explores seven popular open-source databases, including Redis, Neo4J, CouchDB, MongoDB, HBase, Riak, and Postgres. The book delves into their data models, strengths, weaknesses, and real world applications, helping developers choose the right database for their needs.
The Hundred-Page Machine Learning Book by Andriy Burkov is a concise guide to machine learning fundamentals, covering supervised and unsupervised learning, deep learning, model evaluation, and optimization. It includes practical examples for real world applications and is suitable for both beginners and experienced practitioners.

Final Thoughts
This week’s developments underscore a broader trend: the democratization of AI and data tools. Google’s Gemini embeddings and no-code bot sharing lower barriers for developers and non-technical users alike, while Databricks One unifies data access across roles. The emphasis on real-time insights, as seen with Kafka dashboards, reflects the growing need for agility in decision making. Together, these innovations signal a shift towards more inclusive, efficient, and responsive data ecosystems that empower every employee to leverage AI and analytics in their daily work. Organizations that embrace these tools will be better positioned to adapt and thrive in an increasingly data driven world.