
🎧 Listen to the Download
This is an AI generated audio.
Welcome to DevGyan Download ! In this issue we’ll explore how free data APIs can supercharge analytics, how AI is breaking new ground in fluid dynamics, and how Cloudflare’s edge‑first data platform promises lightning‑fast, cost‑effective insights.
Checkout Synoposis, the LinkedIn newsletter where I write about the latest trends and insights for data domain. Download is the detailed version of content covered in Synopsis. You can also listen to the audio version of Download. If you want to stay updated with the latest trends in data, AI, and cloud technologies, you landed at a right place.
AI’s Fresh Take on Classic Fluid Mysteries
For over a century mathematicians have wrestled with fluid‑dynamics equations that describe everything from hurricane vortices to airplane wings. The new DeepMind study introduces an entirely new family of mathematical blow‑ups—unstable singularities—in several complex fluid models. By harnessing physics‑informed neural networks (PINNs) and advanced second‑order optimizers, the team uncovered patterns in the blow‑up speed (λ) across the Incompressible Porous Media (IPM) and Boussinesq equations. These patterns hint at a broader spectrum of unstable solutions, a critical insight because no stable singularities are believed to exist for the 3D Euler or Navier–Stokes equations, the latter being one of the Millennium Prize Problems.
The researchers achieved unprecedented precision—errors comparable to predicting Earth’s diameter within centimeters—by embedding mathematical insights directly into the PINN training loop, ensuring each iteration satisfies the governing equations to near‑machine accuracy. This fusion of deep mathematical theory with cutting‑edge AI promises to transform how we tackle long‑standing challenges in physics, engineering, and beyond.
 Source: Google Deepmind Blog
Source: Google Deepmind Blog
My Take
The paper exemplifies how AI can transcend traditional numerical methods, turning PINNs from solvers into discovery engines. By enforcing physical laws during training, the approach uncovers elusive singularities that would otherwise be hidden in the vast solution space. This not only advances theoretical fluid dynamics but also sets a precedent for future AI‑augmented research across scientific domains.
Unleashing Data Power: Cloudflare’s Serverless Data Platform
Cloudflare has released a trio of edge‑centric tools—Pipelines, R2 Data Catalog, and R2 SQL—that together form a fully serverless workflow for ingesting, storing, and querying event data. Pipelines, built on Workers, accepts structured logs and streams them to an R2 bucket that serves as a lightweight, schema‑aware catalog. The catalog now offers small‑file compaction, rewriting dozens of tiny objects into fewer, larger ones to cut metadata overhead and boost scan speed. No billing occurs during the open‑beta period, but future pricing will include catalog operations and compaction data processing, while R2 storage and class‑A/B operations retain their existing rates. R2 SQL, a distributed query engine that runs directly on Cloudflare’s global network, lets developers write simple SQL queries that hit data where it lives, eliminating the need for external cluster management. The platform is slated to expand with Logpush integration, user‑defined functions, and richer SQL capabilities in 2026.
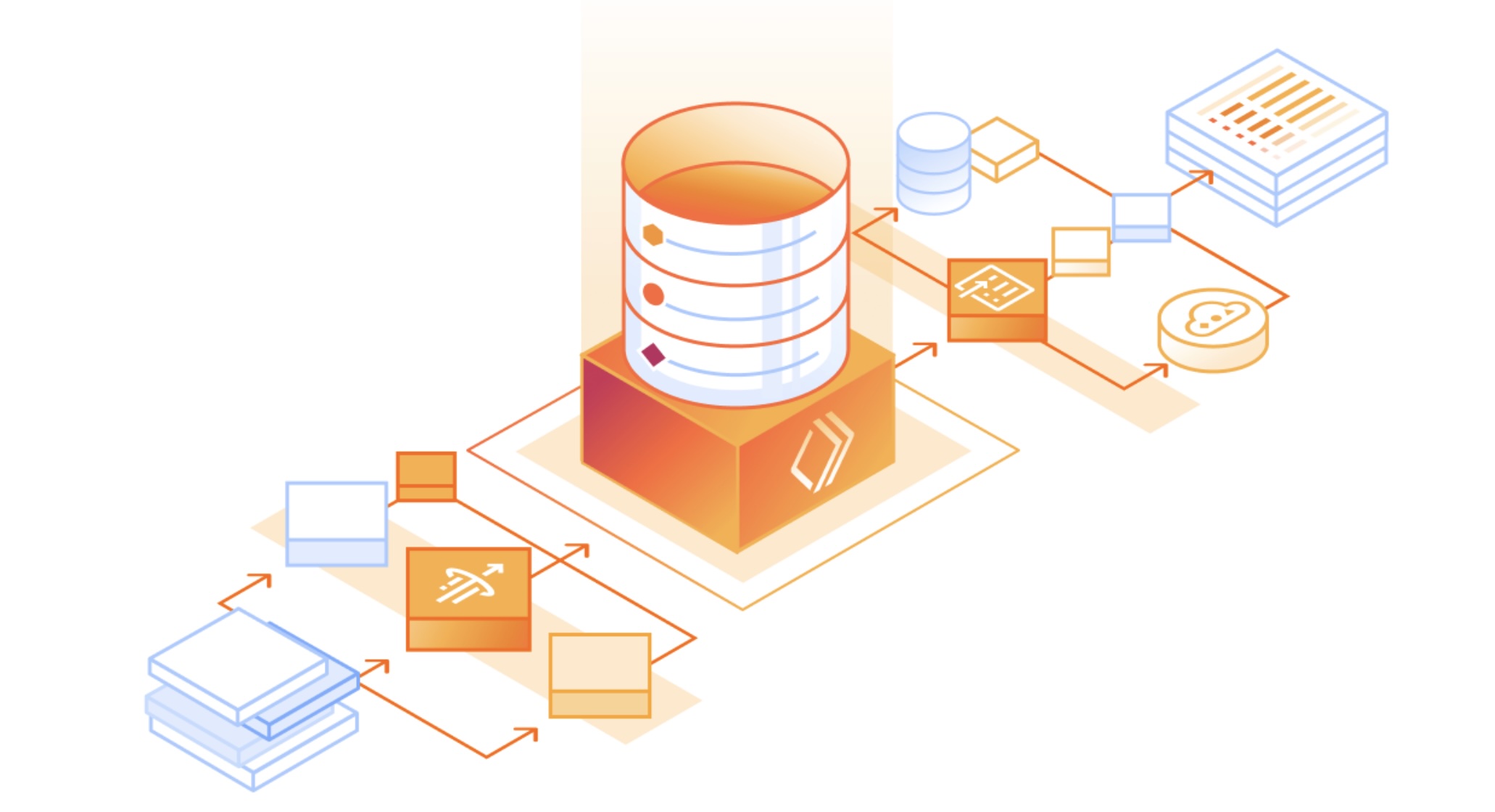 Source: Cloudfare Blog
Source: Cloudfare Blog
My Take
Cloudflare’s edge‑first analytics stack removes a major friction point for data‑driven teams: the burden of provisioning and operating a cluster. By fusing a catalog, compaction, and a serverless SQL engine onto its already massive network, Cloudflare is positioning itself as a true analytics gateway. Early adopters will likely find the current filter‑only SQL limited, but the roadmap suggests a rapid expansion to full aggregation and join support. This initiative is a solid step toward “data as a service” delivered from the network edge, and could reshape how high‑volume event pipelines are built in the coming years.
Data‑Delight: 10 Free APIs to Fuel Your Projects
Exploring real‑time, high‑quality datasets can be a bottleneck for data science workflows. The KDnuggets article curates ten free APIs across five categories—trusted data repositories, web scraping, and web search—to accelerate data collection, integration, and AI agent development. Key highlights include:
-
Community‑Driven Repositories
- Kaggle: Automate downloads with the SDK (
kaggle datasets download -d kingabzpro/world-vaccine-progress -p data --unzip). - Hugging Face: CLI access without an API key unless the dataset is gated (
hf download kingabzpro/dermatology-qa-firecrawl-dataset).
- Kaggle: Automate downloads with the SDK (
-
Web Scraping & Extraction
- Firecrawl: Markdown‑friendly scraping via API.
curl -s -X POST "https://api.firecrawl.dev/v2/scrape" \ -H "Authorization: Bearer $FIRECRAWL_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "url": "https://abid.work", "formats": ["markdown", "html"] }' -
Search APIs
- Tavily: 1,000 free monthly queries; simple JSON responses.
curl --request POST \ --url https://api.tavily.com/search \ --header "Authorization: Bearer <token>" \ --header "Content-Type: application/json" \ --data '{ "query": "who is Leo Messi?", "auto_parameters": false, "topic": "general", "search_depth": "basic", "chunks_per_source": 3, "max_results": 1, "days": 7, "include_answer": true, "include_raw_content": true, "include_images": false, "include_image_descriptions": false, "include_favicon": false, "include_domains": [], "exclude_domains": [], "country": null }' -
Geospatial & Weather
- OpenWeatherMap: Global weather, forecasts, minute‑by‑minute data. (
curl "https://api.openweathermap.org/data/2.5/weather?q=London&appid=YOUR_API_KEY&units=metric") - OpenStreetMap & Overpass API: Query OSM for custom spatial data
curl -G "https://overpass-api.de/api/interpreter" \ --data-urlencode 'data=[out:json];node["amenity"="cafe"](51.50,-0.15,51.52,-0.10);out;' ```. - OpenWeatherMap: Global weather, forecasts, minute‑by‑minute data. (
-
Financial Market Data
- Alpha Vantage: JSON/CSV outputs, 50+ technical indicators.
curl "https://www.alphavantage.co/query?function=TIME_SERIES_DAILY&symbol=IBM&apikey=YOUR_API_KEY"- Yahoo Finance & yfinance: Quick historical prices and fundamentals.
import yfinance as yf print(yf.download("AAPL", period="1y").head()) -
Social Media
- Reddit (PRAW): Fetch posts and comments programmatically.
import praw r = praw.Reddit( client_id="ID", client_secret="SECRET", user_agent="myapp:ds-project:v1 (by u/yourname)" ) print([s.title for s in r.subreddit("Python").hot(limit=5)])- X (Twitter) API: REST endpoints for real‑time content retrieval.
curl -H "Authorization: Bearer YOUR_BEARER_TOKEN" \ "https://api.x.com/2/users/by/username/jack"
The article’s concise code snippets illustrate immediate implementation, making it a handy reference for both novices and seasoned practitioners.
 Source: DevGyan Blog
Source: DevGyan Blog
My Take
The curated list demonstrates a balanced mix of open‑source community assets and robust APIs that cover essential data domains. By leveraging these free endpoints, teams can reduce data acquisition friction, focus on model development, and iterate faster. The inclusion of both high‑level SDKs and raw HTTP calls ensures flexibility across diverse project constraints. Overall, this resource is an indispensable toolbox for anyone looking to inject fresh, real‑time data into their analytics pipelines.
Tool Highlight
RapidMiner is a low-code/no-code data science platform with a visual interface for data preparation, machine learning, and deployment. It offers automated model building, data transformation tools, data visualization, predictive analytics, and text mining. The platform supports various data sources, provides accelerators for common use cases, and includes collaboration features.
![]()
Learning Loop
Database Internals : A deep-dive into how distributed data systems work By Alex Petrov Understanding database internals is crucial for choosing, using, and maintaining databases. However, with many distributed databases and tools available, it’s challenging to understand their differences. This practical guide by Alex Petrov guides developers through modern database and storage engine internals. You’ll explore relevant material from various sources, including books, papers, blog posts, and open-source database source code. The book highlights the key distinctions among modern databases in storage organization and data distribution. It examines storage engines, including classification, taxonomy, B-Tree-based, and immutable log structured storage engines, and their differences and use cases. It also delves into distributed systems, learning how nodes and processes connect and build complex communication patterns, from UDP to reliable consensus protocols. Finally, it explores database clusters and how to achieve consistent models for replicated data.

Final Thoughts
This week’s Download reveals a powerful truth: the cutting edge of data is defined by its accessibility and its reach.
We saw how AI is moving beyond mere prediction to fundamental discovery, with DeepMind using physics-informed networks to uncover new, centuries-old mysteries in fluid dynamics. This isn’t just an academic breakthrough; it’s a blueprint for embedding scientific law directly into machine learning to accelerate discovery across every field.
At the same time, platforms like Cloudflare’s edge-first analytics stack and the plethora of free APIs we highlighted are bringing sophisticated, real-time data ingestion and querying closer to the user—and away from expensive, complicated clusters.
The synthesis is clear: The next generation of success will go to the teams that rapidly combine open data sources with frictionless, edge-based infrastructure to deploy models built on AI-driven scientific rigor. Don’t just analyze the data you have; leverage AI to discover new truths and use serverless tools to deliver those insights everywhere, instantly.
Focus on closing the loop from discovery to deployment, that’s how you stay ahead.