
🎧 Listen to the Download
Hey everyone,
It’s been one month since I officially launched my journey as a dedicated writer on data insights and recent advancements in the industry—and wow, what a ride! In this time, I’ve been consistently inspired by how technology (especially AI) is reshaping our understanding of business intelligence. It’s motivating me to explore these topics even more deeply every week.
This momentum isn’t slowing down anytime soon. It fuels my passion for creating content that helps you navigate these shifts with clarity and confidence. So if you’re looking to stay ahead in data-driven decision making or harness the power of AI, keep an eye out for more insights from me!
Side note: If I’ve learned anything over this past month, it’s that embracing change is key to growth—whether it’s a reader like you or a new algorithm being built. Let’s continue learning together.
Checkout Synoposis, the LinkedIn newsletter where I write about the latest trends and insights for data domain. Download is the detailed version of content covered in Synopsis.
Spark Meets AI: One‑Click Inference with Gemini & Vertex AI
Google Cloud’s latest open‑source Python library lets you run Gemini, Vertex AI, PyTorch, or TensorFlow models directly inside Apache Spark jobs on Dataproc. By mimicking SparkML’s familiar builder pattern, you can call .transform() on a DataFrame and add AI‑powered columns without building a separate inference endpoint.
How It Works
- Spark‑friendly API – Configure a model and call
.transform()just like any SparkML transformer. - Generative AI on columns – Feed a prompt to Gemini and generate new columns (e.g., city → summary).
- Local & Cluster support – Install via PyPI for local testing; deploy on a Dataproc 2.3‑ml cluster for scale.
- Direct model file inference – Use
PyTorchModelHandlerorTensorFlowModelHandlerto load weights from GCS and run batch inference on workers. - Optimizations for large clusters – Built‑in performance tweaks and flexibility for custom options.
Upcoming Enhancements
- Default inclusion in Dataproc ML images.
- Support for Google Cloud Serverless for Apache Spark runtimes.
- Ongoing feature requests via dataproc‑feedback@google.com.
 Source: Google Blog
Source: Google Blog
My Take
From a data‑engineering lens, this library eliminates a major friction point: bridging big‑data pipelines with modern LLMs. The Spark‑style API lowers the learning curve, while on‑cluster inference cuts network latency and simplifies cost management. It’s a practical step toward democratizing AI at scale—developers can iterate faster and focus on data logic rather than orchestration.
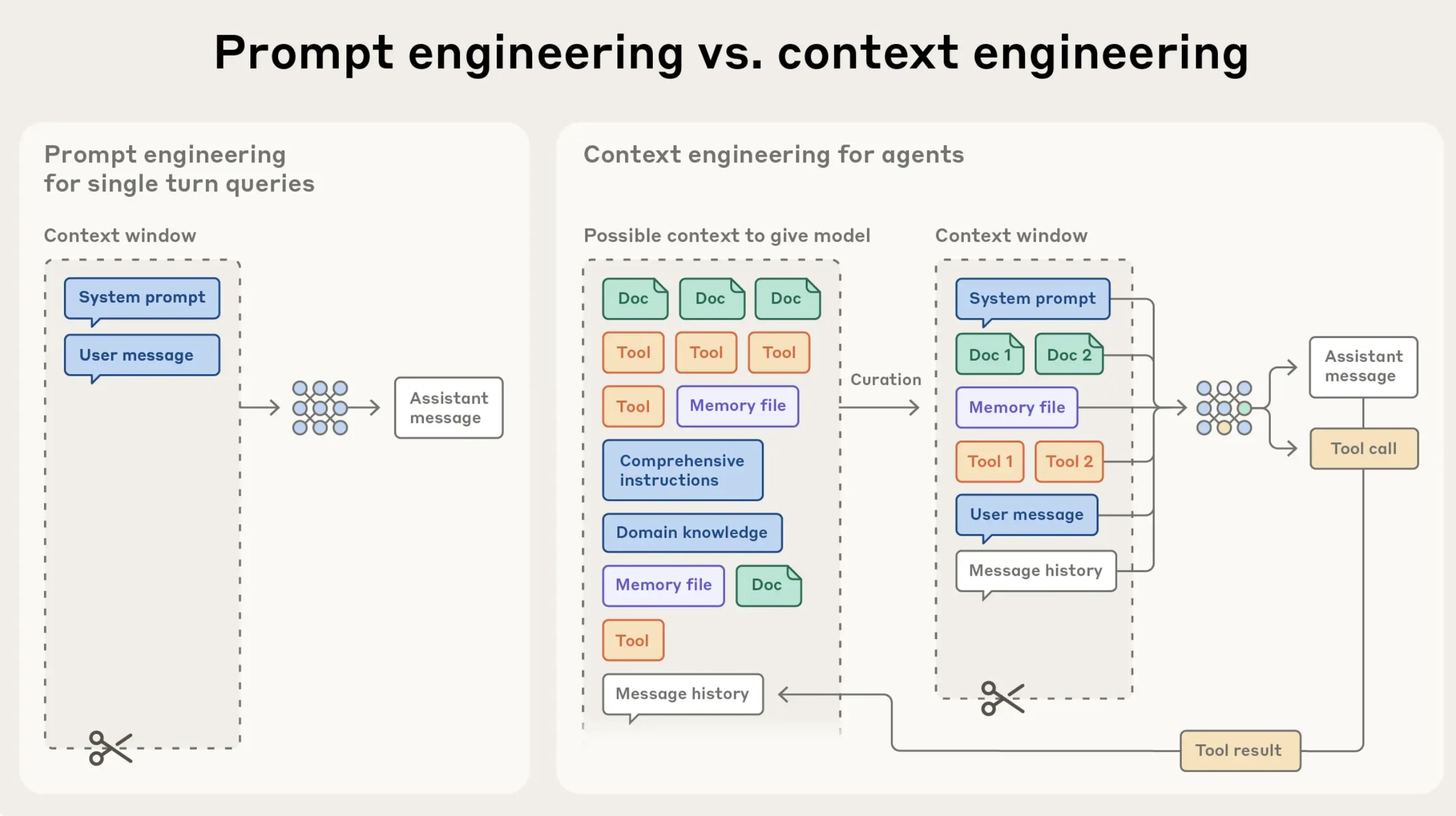
Fine‑Tune Your Attention: Context Engineering Unleashed
The Anthropic Applied AI team explains how context engineering—curating the smallest set of high‑signal tokens that fit within an LLM’s limited attention budget—can dramatically boost agent performance. They cover just‑in‑time data retrieval, hybrid pre‑fetch strategies, and long‑horizon techniques such as compaction, structured note‑taking, and sub‑agent architectures.
Key Takeaways
- Token‑budget is precious – every word costs you focus.
- Just‑in‑time retrieval keeps identifiers in context and loads full data on demand via tools.
- Hybrid strategies blend pre‑fetch for speed with autonomous exploration for depth.
- Compaction summarizes near‑limit conversations to preserve essential details.
- Structured note‑taking gives agents persistent memory outside the model’s window.
- Sub‑agents delegate focused tasks, keeping the main agent’s context clean.
 Source: Anthropic Blog
Source: Anthropic Blog
My Take
As an Applied AI engineer, I view context engineering as the new cornerstone of building reliable agents. Moving beyond perfect prompts to thoughtful curations lets models operate with less prescriptiveness and more autonomy. The techniques described—compaction, just‑in‑time retrieval, and sub‑agents—are not just clever tricks; they’re essential tools for scaling AI systems to real‑world, long‑horizon tasks.
Quick start: Try the Claude Developer Platform’s memory & context cookbook to get hands‑on practice.
DuckDB: The SQL Swiss‑Army Knife for Data Scientists
Quick Take – DuckDB is a lightweight, embedded OLAP database that lets you run fast SQL queries locally, without the heavy setup of a traditional RDBMS. It plays nicely with Pandas, reads Parquet/CSV/JSON, and is free and open‑source.
Key Features
-
Instant, zero‑dependency installation
pip install duckdb==0.6.1One line, no server, no admin overhead.
-
SQL‑first, OLAP‑oriented
• Uses vectorized processing for 20‑40× speed boosts
• ACID guarantees via custom MVCC
• Compatible with familiar SQL dialects (SQLite, MySQL, PostgreSQL) -
Seamless data‑format support
• Native Parquet, CSV, JSON
• Direct integration with Pandas DataFrames -
Open source & MIT licensed – anyone can contribute and extend.
-
Edge‑ready – embed it in any host process to analyze data locally at the edge.
My Take
From a data‑engineering lens, DuckDB eliminates the “install‑and‑tune” bottleneck that plagues many analytics workflows. By marrying SQL’s ubiquity with in‑process, vectorized execution, it lets analysts and scientists slice, dice, and visualize data at near‑real‑time speeds. Its lightweight footprint means you can prototype on a laptop and deploy on the edge without a database cluster. If your team is tired of juggling pandas, NumPy, and external servers, DuckDB offers a clean, ACID‑safe, and high‑performance alternative that keeps the learning curve low and the productivity high.
Final Thoughts
The biggest theme across these updates is the ongoing convergence of big data processing, scalable AI, and high-performance local analytics. The friction between data movement, model integration, and execution speed is rapidly being eliminated by three key approaches: in-pipeline inference, thoughtful agent design, and local OLAP power.
- AI Democratization via Data Pipelines: The new Google Cloud open-source library that brings Gemini, Vertex AI, and other models directly into Apache Spark jobs via a familiar SparkML transform() API is a major win for data engineers.
Key Insight: This eliminates the need to build and manage separate, high-latency inference endpoints, making AI-powered feature generation and batch scoring a seamless, high-scale step in an existing ETL/ELT pipeline. AI is becoming just another column transformation.
- The New Art of Agent Building: Context Engineering: For anyone building reliable, long-running AI agents (not just simple chatbots), Context Engineering is the new cornerstone skill.
Key Insight: The “token budget is precious.” Techniques like Just-in-Time Retrieval, Compaction, and Sub-Agents are mandatory for scaling systems beyond simple, one-off prompts. The focus shifts from perfect prompting to thoughtful data curation to give the LLM the clean, high-signal information it needs to maintain focus and autonomy over long-horizon tasks.
- SQL’s In-Process Renaissance: DuckDB: DuckDB is rapidly becoming the SQL-first Swiss-Army Knife for data scientists and analysts who want fast, local, complex analytics without the overhead of a server-based RDBMS.
Key Insight: By combining SQL’s universal language with an embedded, vectorized OLAP engine, DuckDB offers near-real-time slicing and dicing of files (like Parquet/CSV) and Pandas DataFrames. It drastically lowers the barrier to high-performance analytics, letting teams prototype locally and deploy on the edge with ACID guarantees and zero admin overhead.
My overall message to data practitioners: The divide between data engineering, ML engineering, and analytics is shrinking. Tools like the new Spark/AI library and DuckDB are bringing advanced capabilities to familiar environments (Spark and SQL), while Context Engineering is defining the next generation of scalable, reliable AI applications. Focus on integrating AI and analytics directly into your data flow, and curate the context for your agents like it’s gold.